Are Smaller Models the Future of AI?
The concept of smaller, cost-effective computational models delivering phenomenal performance is gaining increasing traction within the AI research society. This shift aligns precisely with our previous insights eight months ago, especially in complex business decision-making scenarios (Figure 1). For example, LSTMs proved assertive against BERT in text analytics [1]. Recent advancements by Microsoft and the University of Illinois researchers at Urbana–Champaign underscore the validity of our prediction that the future might hold more promise in smaller models rather than large language models (LLMs) [2].

Figure 1: LinkedIn post by Dr Christos Bormpotsis. Image source: https://www.linkedin.com/posts/activity-7121508128814190592-xfBg?utm_source=share&utm_medium=member_desktop
Our recent article delved deeper into modular architectures, drawing inspiration from neuroscience discoveries. Our findings are particularly promising for complex financial fields like Foreign Exchange (Forex) markets [3]. The proposed modular convolutional orthogonal recurrent neural network coupled with Monte-Carlo dropout simulations (MCoRNNMCD-ANN) has proven transformative, enhancing Forex forecasts' accuracy in EUR/GBP price movements (Figure 2).

Figure 2: Architecture of MCoRNNMCD-ANN. Image source: https://www.mdpi.com/2504-2289/7/3/152
More recently, we showed in Figure 3 that the MCoRNNMCD-ANN has been very closed in anticipation of the closing price of EUR/USD [4]. Furthermore, the MCoRNNMCD-ANN as a fintech model empowers traders to make more informed decisions, guiding the ever-evolving finance landscape more effectively than state-of-the-art models from institutions like CERN and Swinburne University of Technology [3].
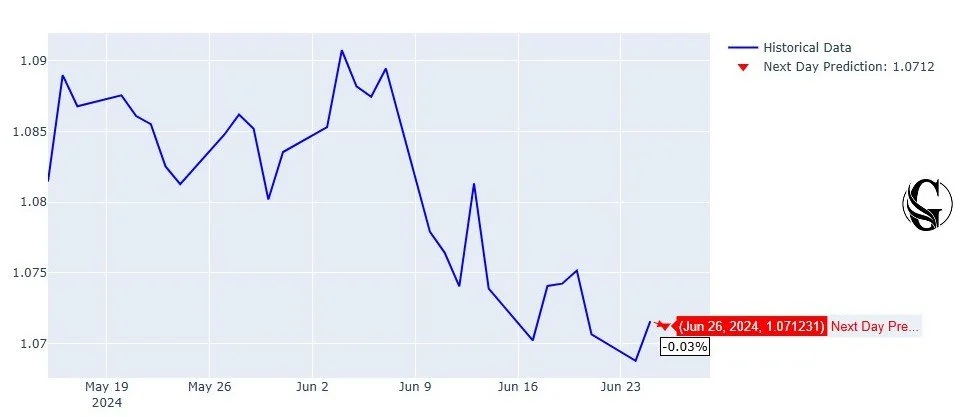
Figure 3: EUR/USD closing price prediction for the next day, June 26th, by Genius Sphere Capital. Image source: https://www.geniusspherecapital.com/analysis/rz2nq02g8irrjqlwo9jeu76gkyat68
Recently, as mentioned above, researchers from Microsoft and the University of Illinois at Urbana–Champaign introduced a hybrid model for Context Language Modeling that handles an unlimited context length, emphasizing how our foresight was correct, namely SAMBA [2]. Efficiently modelling sequences of infinite context length is crucial, as previous models often struggled with quadratic computation complexity or limited extrapolation ability on length generalization.
Architecture of SAMBA
The architecture of SAMBA is a fascinating blend of mixed components, each functioning for a unique purpose in the prevailing model. Central to this architecture is the Mamba layer, a recently proposed State Space Model (SSM) with selective state spaces (Figure 4). This layer enables input-dependent gating to both the recurrent states and the input representation, allowing for a soft selection of the input sequence elements. This feature allows the model to focus on relevant inputs, thereby enabling it to memorize important information over the long term.
One of the critical features of the Mamba layer is its ability to selectively compress a given sequence into recurrent hidden states [5]. This selective compression is crucial as it allows the model to manage the input sequence's complexity effectively. Despite this compression, the Mamba layer can precisely recall memories with the attention mechanism. This balance between compression and recall makes the Mamba layer particularly powerful.

Figure 4: Architecture of SAMBA. Image source: https://arxiv.org/abs/2406.07522
Incorporation of CNNs and RNNs
It is particularly noteworthy to Integrate Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) within the Mamba layer, which incorporates elements of both. CNNs excel at capturing local patterns through convolution operations, making them adept at handling spatial dependencies in data. By incorporating CNNs, the Mamba layer can efficiently process and extract features from input sequences, enhancing the model's ability to focus on relevant data points.
RNNs, on the other hand, are robust in modelling sequential data due to their recurrent connections, which enable them to retain information over time. The Mamba layer leverages the strengths of RNNs to handle temporal dependencies within sequences. This integration ensures that the model can effectively maintain and recall long-term dependencies. By combining CNNs and RNNs elements, the Mamba layer achieves a powerful mechanism for managing the input data's spatial and temporal aspects, significantly enhancing the model's overall performance.
Complementary Layers
Complementing the Mamba layer are the Sliding Window Attention (SWA) layer and the Multi-Layer Perceptron (MLP) layer (Figure 4). The SWA layer addresses the limitations of the Mamba layer in capturing non-Markovian dependencies in sequences. It operates on a window size that slides over the input sequence, ensuring that the computational complexity remains linear concerning the sequence length. The MLP layers serve as the architecture's primary mechanism for nonlinear transformation and recall of factual knowledge.
Performance Evaluation with Other Models
SAMBA significantly surpasses the performance of leading pure attention-based and State Space Model (SSM)-based models across various benchmarks, including common-sense reasoning, language comprehension, mathematics, and coding tasks. SAMBA also showcases exceptional efficiency in handling extended contexts, delivering notable improvements in prompt processing speed and decoding throughput compared to the state-of-the-art Transformer architecture.
Conclusion and Future Predictions
As we continue exploring and developing bio-inspired models like Modular Neural Net architectures, smaller, more efficient models like MCoRNNMCD-ANN and hybrid approaches like SAMBA could be the future. These approaches could offer superior performance and cost-effectiveness, making them ideal for complex decision-making scenarios in various fields. Future research will focus on refining such models, improving their efficiency, and expanding their applications. By leveraging the principles of modularity and other techniques like selective compression, we can create prototypes that handle vast amounts of data and adapt and learn in more nuanced and sophisticated ways. We are on the brink of a new era in computational modelling, where smaller, more efficient architectures will lead the way, providing unparalleled performance and insights across various scientific domains.